
Introduction: Why Database Design Matters
Imagine you’re building a house. You wouldn’t start without a blueprint, right? The same goes for databases. A well-thought-out database design is the blueprint that ensures your data is organized, efficient, and scalable.
At MN Service Providers, we understand that diving into database design can feel overwhelming. But don’t worry—we’re here to guide you through the essentials. In this guide, you’ll learn the fundamentals of database design, from understanding different types of databases to best practices that will set you up for success.
Understanding the Basics of Database Design
What Is Database Design?
Database design is the process of structuring data to ensure it is stored efficiently and can be retrieved easily. Think of it as organizing your digital filing cabinet so that everything is in its right place.
Types of Databases
- Relational Databases: These use tables to store data and are ideal for structured data. Examples include MySQL and PostgreSQL.
- NoSQL Databases: These are more flexible and can handle unstructured data. Examples include MongoDB and Cassandra.
The type you choose is based on your specific needs.
Define Your Data Requirements Clearly
Before you start designing, ask yourself:
- What kind of data will you store?
- How are different data elements related?
- What are the rules governing your data?
Understanding these aspects will help you create a robust database structure.
Start with a Conceptual Data Model
When you’re learning database design how to from the ground up, this is the part where things start to click. Picture this: you’re about to organize a massive garage sale. You have books, clothes, electronics, and toys—how do you keep track of it all? You start by grouping items, labeling boxes, and noting what belongs where. In database terms, that’s exactly what a conceptual data model helps you do.
What Is a Conceptual Data Model?
A conceptual data model is like a bird’s-eye view of your data. It’s a simple and visual way to understand what kind of data you’ll be storing, how the data pieces connect, and what rules they follow. You’re not worried about the technical details yet—just the big picture.
This step is essential in any database design how to guide because it lays the foundation for everything else. You’ll decide:
- What entities (things) you need to track—like Users, Orders, or Products.
- What attributes (details) describe each entity—like a User’s name or a Product’s price.
- How the entities relate to each other—like one User placing many Orders.
Enter the ER Diagram (Entity-Relationship Diagram)
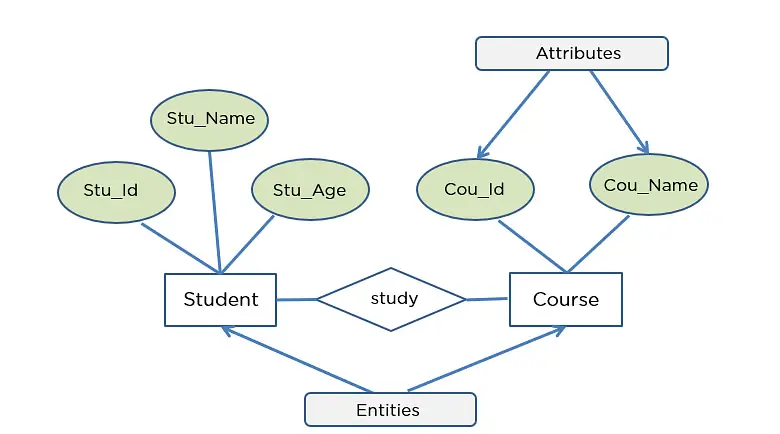
One of the most helpful tools in this stage is the Entity-Relationship (ER) diagram. Think of it as a map where:
- Entities are represented as rectangles (e.g., Customer, Product).
- Attributes are listed inside or around those rectangles (e.g., name, email, price).
- Relationships are lines connecting entities to show how they interact (e.g., a Customer “places” an Order).
Here’s an example to bring it to life:
Imagine you’re building an online bookstore. Your ER diagram might include:
- Entity: Book
- Attributes: title, author, ISBN, price
- Entity: Customer
- Attributes: name, email, phone
- Entity: Order
- Attributes: order_date, order_total
- Relationships: A Customer places many Orders. Each Order contains many Books.
This helps you and your team get on the same page—literally and figuratively—before you start dealing with tables, data types, or SQL.
Why Start Here?
Skipping this step is like skipping a sketch before painting a mural. Without a clear plan, you risk:
- Storing redundant or inconsistent data
- Missing important relationships between data points
- Making design changes late in the project, which is costly and time-consuming
By starting with a conceptual model, you’re not just following good advice—you’re avoiding future headaches.
Best Practices for Conceptual Modeling
To make your conceptual data model effective, keep these tips in mind:
- Use simple language: Avoid jargon, especially when working with non-technical stakeholders.
- Focus on business needs: The model should reflect real-world processes, not technical shortcuts.
- Validate with others: Share your ER diagram with business users or team members to ensure nothing important is missing.
- Don’t overcomplicate: At this stage, keep things simple. You’ll add complexity later in the logical and physical design stages.
Apply the Principles of Normalization
Normalization is the process of organizing data to reduce redundancy. It involves dividing large tables into smaller ones and defining relationships between them.
- First Normal Form (1NF): Ensure that each table column contains atomic (indivisible) values.
- Second Normal Form (2NF): Ensure that all non-key attributes are fully functional dependent on the primary key.
- Third Normal Form (3NF): Ensure that all the attributes are only dependent on the primary key.
Applying these forms helps maintain data integrity and efficiency.
Choose Appropriate Data Types and Naming Conventions
If you’re learning database design how to build a clean, reliable system, think of this step like choosing the right tools for each job in your toolbox. You wouldn’t use a sledgehammer to hang a picture frame, right? In the same way, selecting the correct data types and using clear naming conventions is key to making your database efficient, understandable, and easy to maintain.
Why Data Types Matter
Every column (or field) in your database needs a data type. A data type tells the database what kind of information will be stored in that column. It’s like setting ground rules so the data doesn’t get out of hand.
Here are some common data types you’ll run into:
- INT (or INTEGER): Whole numbers like 1, 23, or 999.
- FLOAT or DECIMAL: Numbers with decimal points, like 3.14 or 99.99.
- VARCHAR(n): Text with a limit, like names or email addresses.
- DATE or DATETIME: For storing calendar dates or timestamps.
- BOOLEAN: True/False or Yes/No values.
Choosing the wrong data type is like pouring soup into a strainer—it leads to messy outcomes. For example, storing phone numbers as integers can strip away important formatting like leading zeros or special characters (e.g., +91-9876543210).
Best Practices for Choosing Data Types
Here are some quick rules of thumb to follow:
- Be precise: Use the smallest data type that meets your needs. It saves space and improves performance.
- Avoid assumptions: Just because something looks like a number doesn’t mean it should be stored as one (like phone numbers or ZIP codes).
- Match the use case: If you need to do math on it, use numeric types. If it’s just for display, text might be better.
This step in database design how to guides is often skipped by beginners, but it can lead to major regrets later. Poor data type choices can slow down queries, cause bugs, and create storage issues.
Naming Conventions: Clarity Is King
Now let’s talk about naming. Your database is going to grow. And when it does, you don’t want to be stuck asking, “What the heck does tbl1 or col_x mean?”
Clear, consistent naming conventions are your best friend. They make your database easier to read, search, and debug—not just for you, but for your teammates and future developers too.
Best Practices for Naming
- Use meaningful names: customer_email is better than ce1.
- Be consistent: Pick a format and stick to it. Some popular styles include:
- snake_case (e.g., order_date)
- camelCase (e.g., orderDate)
- Avoid abbreviations unless they’re common: qty might be okay for quantity, but ctn for “container” could confuse someone else.
- Prefixing (when necessary): For large databases, you might prefix table names (e.g., inv_product for inventory-related tables).
- No spaces or special characters: These can break queries or require escape characters. Use underscores instead of spaces.
Let’s say you’re naming a table that stores customer data. Which would you rather see?
❌ tbl1 with columns col1, col2
✅ customers with columns customer_id, first_name, email_address
The second one reads like a story. The first one reads like a puzzle.
Real-World Analogy
Think of data types and naming conventions like the labels and containers in a professional kitchen. Every ingredient has its own jar—clearly labeled, right size, and stored properly. That way, any chef can walk in and find what they need without wasting time. Your database should work the same way.
Plan for Indexing and Performance from the Start
In the journey of database design how to build a fast and efficient system, indexing is your secret weapon. It’s like adding street signs to a massive city—without them, finding a house would take forever. With them, you get there in seconds.
Too many beginners focus on just storing data. But remember, storing is only half the job. The other half? Retrieving that data quickly and efficiently. That’s where indexing comes in.
What Is an Index in a Database?
An index is a special data structure that makes it faster to find rows in a table based on the values in one or more columns. Think of it like the index at the back of a book. Instead of flipping through every page to find the word “optimization,” you just look it up in the index and go straight to the right page.
Let’s say you have a table of 100,000 customer records. Without an index, the database may need to scan every single row to find the ones you’re searching for. With an index on the right column (like email or customer_id), it can find the answer in milliseconds.
According to a Percona performance study, proper indexing can boost query speed by up to 95%. That’s not just fast—it’s lightning fast.
Types of Indexes You Should Know
As you explore database design how to improve speed and performance, it helps to understand different kinds of indexes:
- Single-column index: Indexes one column, like user_id.
- Composite index: Indexes multiple columns together (e.g., first_name, last_name).
- Unique index: Ensures that the indexed column(s) have unique values—great for fields like email or username.
When to Add Indexes
Here are some smart rules for beginners:
✅ Do add indexes on:
- Primary keys
- Foreign keys
- Columns often used in WHERE, JOIN, or ORDER BY clauses
❌ Don’t add indexes on:
- Columns with low selectivity (e.g., a “gender” field with only M/F)
- Columns that are rarely queried
- Every single column just because you “might need it”
This is one of the key database design how to pitfalls: over-indexing. Too many indexes can slow down inserts, updates, and deletes, because each one needs to be updated every time the data changes.
So, treat indexing like seasoning in cooking—just enough improves the flavor, but too much ruins the dish.
Best Practices for Indexing
- Plan early: Think about how your data will be queried as you design the tables.
- Test often: Use tools like EXPLAIN in SQL to see how your queries use indexes.
- Monitor performance: Track slow queries and adjust indexes as needed.
- Keep an eye on storage: Indexes take up space. Don’t add them carelessly.
Real-Life Scenario
Let’s say you’re building an e-commerce database. Your orders table might have these columns:
- order_id
- customer_id
- order_date
- total_amount
If your users often search their order history by date, you might index the order_date column. If they filter by customer, you’d add an index on customer_id. But you wouldn’t index total_amount unless it’s used regularly in filters or reports.
When to Add Indexes
Here are some smart rules for beginners:
✅ Do add indexes on:
- Primary keys
- Foreign keys
- Columns often used in WHERE, JOIN, or ORDER BY clauses
❌ Don’t add indexes on:
- Columns with low selectivity (e.g., a “gender” field with only M/F)
- Columns that are rarely queried
- Every single column just because you “might need it”
This is one of the key database design how to pitfalls: over-indexing. Too many indexes can slow down inserts, updates, and deletes, because each one needs to be updated every time the data changes.
So, treat indexing like seasoning in cooking—just enough improves the flavor, but too much ruins the dish.
Consider Relationships and Referential Integrity
Imagine you’re building a LEGO city. Each building, road, and vehicle is a separate piece, but they all fit together to make something amazing. In database design how to create reliable systems, the same idea applies—your data tables must connect correctly and follow the right rules. That’s where relationships and referential integrity come into play.
What Are Relationships in a Database?
Relationships define how one table’s data connects to another. There are three main types you need to know:
- One-to-One (1:1): One record in Table A matches one record in Table B.
Example: Each person has one passport. - One-to-Many (1:N): One record in Table A links to many records in Table B.
Example: One customer can place many orders. - Many-to-Many (M:N): Records in Table A can relate to many in Table B and vice versa.
Example: Students enrolled in multiple classes.
Understanding these relationships is crucial when learning database design how to structure your tables properly. Get it wrong, and you might end up with missing or duplicated data—like a puzzle with the wrong pieces jammed together.
Primary Keys and Foreign Keys
To build these relationships, you need two essential tools:
- Primary Key: This is the unique identifier for a row in a table. Think of it as a fingerprint—no two rows can have the same one.
- Foreign Key: This links to the primary key of another table, showing how rows are related.
For example, in an e-commerce site:
- The Customers table might have a customer_id as the primary key.
- The Orders table includes a customer_id as a foreign key, showing who placed each order.
This setup ensures every order is tied to a valid customer. It also protects against orphaned data (like orders without owners).
Why Referential Integrity Matters
Referential integrity means that your database keeps these relationships consistent. It prevents mistakes like:
- Deleting a customer while their orders still exist.
- Adding an order that points to a non-existent customer.
According to a Data Integrity Report, bad data costs businesses an average of $12.9 million per year. That’s a steep price to pay for broken links and messy relationships.
To maintain referential integrity:
- Use foreign key constraints: These enforce rules automatically, ensuring related data stays valid.
- Enable cascade options if needed: For example, when a customer is deleted, you can set their orders to be deleted too—or preserved, depending on your needs.
Helpful Tips for Beginners
- Always define primary keys first: This gives your data structure and reliability.
- Use consistent data types for foreign keys: If customer_id is an INT in one table, it should be the same in the related table.
- Name your keys clearly: Use names like fk_orders_customer_id instead of just id.
Design with Scalability and Maintenance in Mind
Let’s face it—no one builds a house expecting it to fall apart in a year. You plan for the future: extra rooms, stronger foundations, maybe even solar panels. The same rule applies in database design how to create something sustainable and future-proof. If your database can’t grow with your business or be easily maintained, you’re building on shaky ground.
What Is Scalability?
Scalability means your database can handle more data, more users, or more traffic without crashing or slowing to a crawl. Imagine you launch a small app today with 100 users. But what if next year, you hit 100,000 users? Will your database survive—or surrender?
How to Design for Scalability
Here are some practical ways to make sure your design scales well:
- Keep it Modular
Break your database into logical parts or modules. For example, separate tables for users, orders, payments, and products—don’t lump everything into one “mega table.”
This modular approach lets you add or change parts without breaking the whole system.
- Avoid Redundancy
Repeating the same data across multiple tables not only wastes space—it creates maintenance nightmares. Always refer back to normalization and relationships to keep your design lean.
- Think About Sharding and Partitioning
As your data grows, splitting it into shards (smaller databases across servers) or partitions (sections of a table) can improve speed and reliability. You don’t need to implement this on day one, but design your schema so it’s possible later.
- Limit Hard-Coding
Don’t hard-code values into your design. Instead of putting the payment status “Paid” into every row, create a payment_status table. This gives you flexibility to change or expand options without touching every record.
Why Maintenance Matters
Even the best databases need regular updates—like changing a column, adding a new feature, or correcting data. If your design is messy, each change becomes risky. But a clean structure makes maintenance easier and safer.
Best Practices for Easy Maintenance
- Document Everything: Every table, column, constraint, and rule should be documented. This helps current and future developers understand what’s going on without guesswork.
- Use Version Control for Scripts: Just like developers use Git for code, use tools like Git or Liquibase for tracking database schema changes. It’s a lifesaver when you need to roll back changes or sync environments.
- Use Descriptive Comments: Add comments in your schema where necessary. Explain tricky relationships, unusual data types, or reasons behind certain decisions.
- Test Before Deployment: Always test changes in a development or staging environment before updating your live database. Mistakes in production can be catastrophic.
Real-Life Example
Let’s say you create a table for storing blog comments, and you use VARCHAR(255) to store the actual comment text. Works fine today. But what happens when users want to leave longer messages or formatted content? If you had used TEXT instead, you’d have more flexibility with less redesign later.
This is a classic database design how to tip: Plan ahead, but stay flexible.
Conclusion
Designing a database is like building a strong foundation for your data-driven applications. By following these best practices, you’ll create a database that’s efficient, scalable, and easy to maintain.
For further learning, consider exploring resources like:
- Database Design Basics – Microsoft Support
- Mastering Database Design: An Ultimate Guide | GeeksforGeeks
- Database Normalization – Normal Forms
At MN Service Providers, we’re committed to helping you navigate the complexities of database design. Please don’t hesitate to contact us for personalized guidance and support.
Frequently Asked Questions (FAQ)
Designing a database involves several key steps. First, understand your data requirements by identifying entities and relationships. Then, create a conceptual data model using ER diagrams, normalize your tables to reduce redundancy, and define keys and constraints. Finally, choose appropriate data types, plan indexing, and implement the schema in your preferred database system.
The 7 phases of database design typically include:
- Requirements gathering
- Conceptual design
- Logical design
- Schema refinement (normalization)
- Physical design
- Implementation
- Maintenance
Each phase builds on the previous one to create a well-structured and scalable database system.
To draw a database schema, start by listing all entities (like users, orders, or products) and their attributes. Then, define relationships between them and assign primary and foreign keys. You can use tools like dbdiagram.io, Lucidchart, or MySQL Workbench to visually represent your tables, fields, and connections in a clear diagram.
A database design diagram, often called an ER (Entity-Relationship) diagram or schema diagram, is a visual representation of your database structure. It shows how tables (entities) relate to one another and includes keys, attributes, and relationships. These diagrams help developers, analysts, and stakeholders understand the database layout before implementation.
A DBMS (Database Management System) package is software that helps you create, manage, and interact with databases. It handles tasks like storing data, enforcing rules, running queries, and managing users. Examples include MySQL, PostgreSQL, Oracle Database, and Microsoft SQL Server.
SQL (Structured Query Language) is the standard language used to interact with a DBMS. It allows you to create tables, insert and retrieve data, update records, and manage database permissions. Whether you’re designing a small app or a large-scale system, SQL is a core part of understanding database design how to build and query structured data efficiently.
Melvin C Varghese is an author with more than 8 years of expertise in DevOps, SEO and SEM. His portfolio blogs include a Digital Marketing blog at https://melvincv.com/blog/ and a DevOps blog at https://blog.melvincv.com/. He is married with 2 small kids and is a simple person who eats, sleeps, works and plays. He loves music, comedy movies and the occasional video game.